建议 87:充分利用 set 的优势
Python 中集合是通过 Hash 算法实现的无序不重复的元素集。
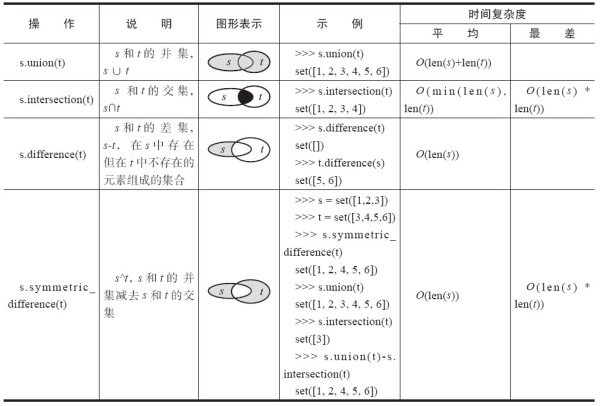
我们来做一些测试:
$ python -m timeit -n 1000 "[x for x in range(1000) if x in range(600, 1000)]"
1000 loops, best of 3: 6.44 msec per loop
$ python -m timeit -n 1000 "set(range(100)).intersection(range(60, 100))"
1000 loops, best of 3: 9.18 usec per loop
实际上 set 的 union、intersection、difference 等操作要比 list 的迭代要快。因此如果涉及求 list 交集、并集或者差等问题可以转换为 set 来操作。
建议 88:使用 multiprocess 克服 GIL 的缺陷
多进程 Multiprocess 是 Python 中的多进程管理包,在 Python2.6 版本中引进的,主要用来帮助处理进程的创建以及它们之间的通信和相互协调。它主要解决了两个问题:一是尽量缩小平台之间的差异,提供高层次的 API 从而使得使用者忽略底层 IPC 的问题;二是提供对复杂对象的共享支持,支持本地和远程并发。
类 Process 是 multiprocess 中较为重要的一个类,用户创建进程,其构造函数如下:
Process([group[, target[, name[, args[, kwargs]]]]])
其中,参数 target 表示可调用对象;args 表示调用对象的位置参数元组;kwargs 表示调用对象的字典;name 为进程的名称;group 一般设置为 None。该类提供的方法与属性基本上与 threading.Thread 一致,包括 is_alive()、join([timeout])、run()、start()、terminate()、daemon(要通过 start() 设置)、exitcode、name、pid 等。
不同于线程,每个进程都有其独立的地址空间,进程间的数据空间也相互独立,因此进程之间数据的共享和传递不如线程来得方便。庆幸的是 multiprocess 模块中都提供了相应的机制:如进程间同步操作原语 Lock、Event、Condition、Semaphore,传统的管道通信机制 pipe 以及队列 Queue,用于共享资源的 multiprocess.Value 和 multiprocess.Array 以及 Manager 等。
Multiprocessing 模块在使用上需要注意以下几个要点:
1.进程之间的的通信优先考虑 Pipe 和 Queue,而不是 Lock、Event、Condition、Semaphore 等同步原语。进程中的类 Queue 使用 pipe 和一些 locks、semaphores 原语来实现,是进程安全的。该类的构造函数返回一个进程的共享队列,其支持的方法和线程中的 Queue 基本类似,除了方法 task_done()和 join() 是在其子类 JoinableQueue 中实现的以外。需要注意的是,由于底层使用 pipe 来实现,使用 Queue 进行进程之间的通信的时候,传输的对象必须是可以序列化的,否则 put 操作会导致 PicklingError。此外,为了提供 put 方法的超时控制,Queue 并不是直接将对象写到管道中而是先写到一个本地的缓存中,再将其从缓存中放入 pipe 中,内部有个专门的线程 feeder 负责这项工作。由于 feeder 的存在,Queue 还提供了以下特殊方法来处理进程退出时缓存中仍然存在数据的问题。
1.1close():表明不再存放数据到 queue 中。一旦所有缓冲的数据刷新到管道,后台线程将退出。
1.2join_thread():一般在 close 方法之后使用,它会阻止直到后台线程退出,确保所有缓冲区中的数据已经刷新到管道中。
1.3cancel_join_thread():需要立即退出当前进程,而无需等待排队的数据刷新到底层管道的时候可以使用该方法,表明无须阻止到后台进程的退出。
Multiprocessing 中还有个 SimpleQueue 队列,它是实现了锁机制的 pipe,内部去掉了 buffer,但没有提供 put 和 get 的超时处理,两个动作都是阻塞的。
除了 multiprocessing.Queue 之外,另一种很重要的通信方式是 multiprocessing.Pipe。它的构造函数为 multiprocess.Pipe([duplex]),其中 duplex 默认为 True,表示为双向管道,否则为单向。它返回一个 Connection 对象的组(conn1, conn2),分别表示管道的两端。Pipe 不支持进程安全,因此当有多个进程同时对管道的一端进行读操作或者写操作的时候可能会导致数据丢失或者损坏。因此在进程通信的时候,如果是超过 2 个以上的线程,可以使用 queue,但对于两个进程之间的通信而言 Pipe 性能更快。
from multiprocessing import Process, Pipe, Queue
import time
def reader_pipe(pipe):
output_p, input_p = pipe # 返回管道的两端
inout_p.close()
while True:
try:
msg = output_p.recv() # 从 pipe 中读取消息
except EOFError:
break
def writer_pipe(count, input_p): # 写消息到管道中
for i in range(0, count):
input_p.send(i) # 发送消息
def reader_queue(queue): # 利用队列来发送消息
while True:
msg = queue.get() # 从队列中获取元素
if msg == "DONE":
break
def writer_queue(count, queue):
for ii in range(0, count):
queue.put(ii) # 放入消息队列中
queue.put("DONE")
if __name__ == "__main__":
print("testing for pipe:")
for count in [10 ** 3, 10 ** 4, 10 ** 5]:
output_p, input_p = Pipe()
reader_p = Process(target=reader_pipe, args=((output_p, input_p),))
reader_p.start() # 启动进程
output_p.close()
_start = time.time()
writer_pipe(count, input_p) # 写消息到管道中
input_p.close()
reader_p.join() # 等待进程处理完毕
print("Sending {} numbers to Pipe() took {} seconds".format(count, (time.time() - _start)))
print("testsing for queue:")
for count in [10 ** 3, 10 ** 4, 10 ** 5]:
queue = Queue() # 利用 queue 进行通信
reader_p = Process(target=reader_queue, args=((queue),))
reader_p.daemon = True
reader_p.start()
_start = time.time()
writer_queue(count, queue) # 写消息到 queue 中
reader_p.join()
print("Seding {} numbers to Queue() took {} seconds".format(count, (time.time() - _start)))
上面代码分别用来测试两个多线程的情况下使用 pipe 和 queue 进行通信发送相同数据的时候的性能,从函数输出可以看出,pipe 所消耗的时间较小,性能更好。
2.尽量避免资源共享。相比于线程,进程之间资源共享的开销较大,因此要尽量避免资源共享。但如果不可避免,可以通过 multiprocessing.Value 和 multiprocessing.Array 或者 multiprocessing.sharedctpyes 来实现内存共享,也可以通过服务器进程管理器 Manager() 来实现数据和状态的共享。这两种方式各有优势,总体来说共享内存的方式更快,效率更高,但服务器进程管理器 Manager() 使用起来更为方便,并且支持本地和远程内存共享。
# 示例一
import time
from multiprocessing import Process, Value
def func(val): # 多个进程同时修改 val
for i in range(10):
time.sleep(0.1)
val.value += 1
if __name__ == "__main__":
v = Value("i", 0) # 使用 value 来共享内存
processList = [Process(target=func, args=(v,)) for i in range(10)]
for p in processList: p.start()
for p in processList: p.join()
print v.value
# 修改 func 函数,真正控制同步访问
def func(val):
for i in range(10):
time.sleep(0.1)
with val.get_lock(): # 仍然需要使用 get_lock 方法来获取锁对象
val.value += 1
# 示例二
import multiprocessing
def f(ns):
ns.x.append(1)
ns.y.append("a")
if __name__ == "__main__":
manager = multiprocessing.Manager()
ns = manager.Namespace()
ns.x = [] # manager 内部包括可变对象
ns.y = []
print("before process operation: {}".format(ns))
p = multiprocessing.Process(target=f, args=(ns,))
p.start()
p.join()
print("after process operation {}".format(ns)) # 修改根本不会生效
# 修改
import multiprocessing
def f(ns, x, y):
x.append(1)
y.append("a")
ns.x = x # 将可变对象也作为参数传入
ns.y = y
if __name__ == "__main__":
manager = multiprocessing.Manager()
ns = manager.Namespace()
ns.x = [] # manager 内部包括可变对象
ns.y = []
print("before process operation: {}".format(ns))
p = multiprocessing.Process(target=f, args=(ns, ns.x, ns.y))
p.start()
p.join()
print("after process operation {}".format(ns))
3.注意平台之间的差异。由于 Linux 平台使用 fork() 来创建进程,因此父进程中所有的资源,如数据结构、打开的文件或者数据库的连接都会在子进程中共享,而 Windows 平台中父子进程相对独立,因此为了更好地保持平台的兼容性,最好能够将相关资源对象作为子进程的构造函数的参数传递进去。要避免如下方式:
f = None
def child(f):
# do something
if __name__ == "__main__":
f = open(filename, mode)
p = Process(target=child)
p.start()
p.join()
# 推荐的方式
def child(f):
print(f)
if __name__ == "__main__":
f = open(filename, mode)
p = Process(target=child, args=(f, )) # 将资源对象作为构造函数参数传入
p.start()
p.join()
需要注意的是,Linux 平台上 multiprocessing 的实现是基于 C 库中的 fork(),所有子进程与父进程的数据是完全相同,因此父进程中所有的资源,如数据结构、打开的文件或者数据库的连接都会在子进程中共享。但 Windows 平台上由于没有 fork() 函数,父子进程相对独立,因此保持了平台的兼容性,最好在脚本中加上 if __ name __ == “ __ main __” 的判断,这样可以避免出现 RuntimeError 或者死锁。
4.尽量避免使用 terminate() 方式终止进程,并且确保 pool.map 中传入的参数是可以序列化的。
import multiprocessing
def unwrap_self_f(*args, **kwargs):
return calculate.f(*args, **kwargs) # 返回一个对象
class calculate(object):
def f(self, x):
return x * x
def run(self):
p = multiprocessing.Pool()
return p.map(unwrap_self_f, zip([self] * 3, [1, 2, 3]))
if __name__ == "__main__":
c1 = calculate()
print(c1.run())
建议 89:使用线程池提高效率
我们知道线程的生命周期分为 5 个状态:创建、就绪、运行、阻塞和终止。自线程创建到终止,线程便不断在运行、就绪和阻塞这 3 个状态之间转换直至销毁。而真正占有 CPU 的只有运行、创建和销毁这 3 个状态。一个线程的运行时间由此可以分为 3 部分:线程的启动时间(Ts)、线程体的运行时间(Tr)以及线程的销毁时间(Td)。在多线程处理的情境中,如果线程不能够被重用,就意味着每次创建都需要经过启动、销毁和运行这 3 个过程。这必然会增加系统的相应时间,降低效率。而线程体的运行时间 Tr 不可控制,在这种情况下要提高线程运行的效率,线程池便是一个解决方案。
线程池通过实现创建多个能够执行任务的线程放入池中,所要执行的任务通常被安排在队列中。通常情况下,需要处理的任务比线程的数目要多,线程执行完当前任务后,会从队列中取下一个任务,直到所有的任务已经完成。
由于线程预先被创建并放入线程池中,同时处理完当前任务之后并不销毁而是被安排处理下一个任务,因此能够避免多次创建线程,从而节省线程创建和销毁的开销,带来更好的性能和系统稳定性。线程池技术适合处理突发性大量请求或者需要大量线程来完成任务、但任务实际处理时间较短的应用场景,它能有效避免由于系统中创建线程过多而导致的系统性能负载过大、响应过慢等问题。
Python 中利用线程池有两种解决方案:一是自己实现线程池模式,二是使用线程池模块。
先来看一个线程池模式的简单实现:线程池代码
本段代码偏长,编辑到知乎上始终无法保存,只好贴我的博客地址,各位可转到博客去看。 自行实现线程,需要定义一个 Worker 处理工作请求,定义 WorkerManager 来进行线程池的管理和创建,它包含一个工作请求队列和执行结果队列,具体的下载工作通过 download_file 方法实现。
相比自己实现的线程池模型,使用现成的线程池模块往往更简单。Python 中线程池模块的下载地址。该模块提供了以下基本类和方法:
1.threadpool.ThreadPool:线程池类,主要的作用是用来分派任务请求和收集运行结果。主要有以下方法:
1.1init(self, num_workers, q_size=0, resq_size=0, poll_timeout=5):建立线程池,并启动对应 num_workers 的线程;q_size 表示任务请求队列的大小,resq_size 表示存放运行结果队列的大小。
1.2createWorkers(self, num_workers, poll_timeout=5):将 num_workers 数量对应的线程加入线程池中。
1.3dismissWorkers(self, num_workers, do_join=False):告诉 num_workers 数量的工作线程当执行完当前任务后退出
1.4joinAllDismissedWorkers(self):在设置为退出的线程上执行 Thread.join
1.5putRequest(self, request, block=True, timeout=None):将工作请求放入队列中
1.7poll(self, block=False):处理任务队列中新的请求wait(self):阻塞用于等待所有执行结果。注意当所有执行结果返回后,线程池内部的线程并没有销毁,而是在等待新的任务。因此,wait() 之后仍然可以再次调用 pool.putRequests()往其中添加任务
2.threadpool.WorkRequest:包含有具体执行方法的工作请求类
3.threadpool.WorkerThread:处理任务的工作线程,主要有 run() 方法以及 dismiss() 方法。
4.makeRequests(callable_, args_list, callback=None, exec_callback=_handle_thread_exception):主要函数,作用是创建具有相同的执行函数但参数不同的一系列工作请求。
再来看一个线程池实现的例子:
import urllib2
import os
import time
import threadpool
def download_file(url):
print("begin download {}".format(url ))
urlhandler = urllib2.urlopen(url)
fname = os.path.basename(url) + ".html"
with open(fname, "wb") as f:
while True:
chunk = urlhandler.read(1024)
if not chunk:
break
f.write(chunk)
urls = ["http://wiki.python.org/moni/WebProgramming",
"https://www.createspace.com/3611970",
"http://wiki.python.org/moin/Documention"]
pool_size = 2
pool = threadpool.ThreadPool(pool_size) # 创建线程池,大小为 2
requests = threadpool.makrRequests(download_file, urls) # 创建工作请求
[pool.putRequest(req) for req in requests]
print("putting request to pool")
pool.putRequest(threadpool.WorkRequest(download_file, args=["http://chrisarndt.de/projects/threadpool/api/",])) # 将具体的请求放入线程池
pool.putRequest(threadpool.WorkRequest(download_file, args=["https://pypi.python.org/pypi/threadpool",]))
pool.poll() # 处理任务队列中的新的请求
pool.wait()
print("destory all threads before exist")
pool.dismissWorkers(pool_size, do_join=True) # 完成后退出
建议 90:使用 C/C++ 模块扩展高性能
Python 具有良好的可扩展性,利用 Python 提供的 API,如宏、类型、函数等,可以让 Python 方便地进行 C/C++ 扩展,从而获得较优的执行性能。所有这些 API 却包含在 Python.h 的头文件中,在编写 C 代码的时候引入该头文件即可。
来看一个简单的例子:
1、先用 C 实现相关函数,实现素数判断,也可以直接使用 C 语言实现相关函数功能后再使用 Python 进行包装。
#include "Python.h"
static PyObject * pr_isprime(PyObject, *self, PyObject * args) {
int n, num;
if (!PyArg_ParseTuple(args, "i", &num)) // 解析参数
return NULL;
if (num < 1) {
return Py_BuildValue("i", 0); // C 类型的数据结构转换成 Python 对象
}
n = num - 1;
while (n > 1) {
if (num % n == 0) {
return Py_BuildValue("i", 0);
n--;
}
}
return Py_BuildValue("i", 1);
}
static PyMethodDef PrMethods[] = {
{"isPrime", pr_isprime, METH_VARARGS, "check if an input number is prime or not."},
{NULL, NULL, 0, NULL}
};
void initpr(void) {
(void) Py_InitModule("pr", PrMethods);
}
上面的代码包含以下 3 部分:
1.1导出函数:C 模块对外暴露的接口函数 pr_isprime,带有 self 和 args 两个参数,其中参数 args 中包含了 Python 解释器要传递给 C 函数的所有参数,通常使用函数 PyArg_ParseTuple() 来获得这些参数值
1.2初始化函数:以便 Python 解释器能够对模块进行正确的初始化,初始化时要以 init 开头,如 initp
1.3方法列表:提供给外部的 Python 程序使用的一个 C 模块函数名称映射表 PrMethods。它是一个 PyMethodDef 结构体,其中成员依次表示方法名、导出函数、参数传递方式和方法描述。看下面的例子:
struct PyMethodDef {
char * m1_name; // 方法名
PyCFunction m1_meth; // 导出函数
int m1_flags; // 参数传递方法
char * m1_doc; // 方法描述
} 参数传递方法一般设置为 METH_VARARGS,如果想传入关键字参数,则可以将其与 METH_KEYWORDS 进行或运算。若不想接受任何参数,则可以将其设置为 METH_NOARGS。该结构体必须与 {NULL, NULL, 0, NULL} 所表示的一条空记录来结尾。
2、编写 setup.py 脚本。
from distutils.core import setup, Extension
module = Extension("pr", sources=["testextend.c"])
setup(name="Pr test", version="1.0", ext_modules=[module])
3、使用 python setup.py build 进行编译,系统会在当前目录下生成一个 build 子目录,里面包含 pr.so 和 pr.o 文件。
4、将生成的文件 py.so 复制到 Python 的 site_packages 目录下,或者将 pr.so 所在目录的路径添加到 sys.path 中,就可以使用 C 扩展的模块了。
更多关于 C 模块扩展的内容请读者参考 。
建议 91:使用 Cython 编写扩展模块
Python-API 让大家可以方便地使用 C/C++ 编写扩展模块,从而通过重写应用中的瓶颈代码获得性能提升。但是,这种方式仍然有几个问题:
1.掌握 C/C++ 编程语言、工具链有巨大的学习成本
2.即便是 C/C++ 熟手,重写代码也有非常多的工作,比如编写特定数据结构、算法的 C/C++ 版本,费时费力还容易出错
所以整个 Python 社区都在努力实现一个 ”编译器“,它可以把 Python 代码直接编译成等价的 C/C++ 代码,从而获得性能提升,如 Pyrex、Py2C 和 Cython 等。而从 Pyrex 发展而来的 Cython 是其中的集大成者。
Cython 通过给 Python 代码增加类型声明和直接调用 C 函数,使得从 Python 代码中转换的 C 代码能够有非常高的执行效率。它的优势在于它几乎支持全部 Python 特性,也就是说,基本上所有的 Python 代码都是有效的 Cython 代码,这使得将 Cython 技术引入项目的成本降到最低。除此之外,Cython 支持使用 decorator 语法声明类型,甚至支持专门的类型声明文件,以使原有的 Python 代码能够继续保持独立,这些特性都使得它得到广泛应用,比如 PyAMF、PyYAML 等库都使用它编写自己的高效率版本。
# 安装
$ pip install -U cython
# 生成 .c 文件
$ cython arithmetic.py
# 提交编译器
$ gcc -shared -pthread -fPIC -fwrapv -02 -Wall -fno-strict-aliasing -I /usr/include/python2.7 -o arithmetic.so arithmetic.c
# 这时生成了 arithmetic.so 文件
# 我们就可以像 import 普通模块一样使用它
每一次都需要编译、等待有点麻烦,所以 Cython 很体贴地提供了无需显式编译的方案:pyximport。只要将原有的 Python 代码后缀名从 .py 改为 .pyx 即可。
$ cp arithmetic.py arithmetic.pyx
$ cd ~
$ python
>>> import pyximport; pyximport.install()
>>> import arithmetic
>>> arithmetic.__file__
从 __ file __ 属性可以看出,这个 .pyx 文件已经被编译链接为共享库了,pyximport 的确方便啊!
接下来我们看看 Cython 是如何提升性能的。
在 GIS 中,经常需要计算地球表面上两点之间的距离:
import math
def great_circle(lon1, lat1, lon2, lat2):
radius = 3956 # miles
x = math.pi / 180.0
a = (90.0 - lat1) * (x)
b = (90.0 - lat2) * (x)
theta = (lon2 - lon1) * (x)
c = math.acos(math.cos(a) * math.cos(b)) + (math.sin(a) * math.sin(b) * math.cos(theta))
return radius * c
接下来尝试 Cython 进行改写:
import math
def great_circle(float lon1, float lat1, float lon2, float lat2):
cdef float radius = 3956.0
cdef float pi = 3.14159265
cdef float x = pi / 180.0
cdef float a, b, theta, c
a = (90.0 - lat1) * (x)
b = (90.0 - lat2) * (x)
theta = (lon2 - lon1) * (x)
c = math.acos(math.cos(a) * math.cos(b)) + (math.sin(a) * math.sin(b) * math.cos(theta))
return radius * c
通过给 great_circle 函数的参数、中间变量增加类型声明,Cython 代码业务逻辑代码一行没改。使用 timeit 库可以测定提速将近 2 成,说明类型声明对性能提升非常有帮助。这时候,还有一个性能瓶颈,调用的 math 库是一个 Python 库,性能较差,可以直接调用 C 函数来解决:
cdef extern from "math.h":
float cosf(float theta)
float sinf(float theta)
float acosf(float theta)
def greate_circle(float lon1, float lat1, float lon2, float lat2):
cdef float radius = 3956.0
cdef float pi = 3.14159265
cdef float x = pi / 180.0
cdef float a, b, theta, c
a = (90.0 - lat1) * (x)
b = (90.0 - lat2) * (x)
theta = (lon2 - lon1) * (x)
c = acosf((cosf(a) * cosf(b)) + (sinf(a) * sinf(b) * cosf(theta)))
return radius * c
Cython 使用 cdef extern from 语法,将 math.h 这个 C 语言库头文件里声明的 cofs、sinf、acosf 等函数导入代码中。因为减少了 Python 函数调用和调用时产生的类型转换开销,使用 timeit 测试这个版本的代码性能提升了 5 倍有余。
通过这个例子,可以掌握 Cython 的两大技能:类型声明和直接调用 C 函数。比起直接使用 C/C++ 编写扩展模块,使用 Cython 的方法方便得多。
除了使用 Cython 编写扩展模块提升性能之外,Cython 也可以用来把之前编写的 C/C++ 代码封装成 .so 模块给 Python 调用(类似 boost.python/SWIG 的功能),Cython 社区已经开发了许多自动化工具。