第 6 章 内部机制
建议 61:使用更加安全的 property
property 实际上是一种实现了 __ get __ () 、 __ set __ () 方法的类,用户也可以根据自己的需要定义个性化的 property,其实质是一种特殊的数据描述符(数据描述符:如果一个对象同时定义了 __ get __ () 和 __ set __ () 方法,则称为数据描述符,如果仅定义了__get__() 方法,则称为非数据描述符)。它和普通描述符的区别在于:普通描述符提供的是一种较为低级的控制属性访问的机制,而 property 是它的高级应用,它以标准库的形式提供描述符的实现,其签名形式为:
property(fget=None, fset=None, fdel=None, doc=None) -> property attribute
property 有两种常用的形式:
1、第一种形式
class Some_Class(object):
def __init__(self):
self._somevalue = 0
def get_value(self):
print('calling get method to return value')
return self._somevalue
def set_value(self, value):
print('calling set method to set value')
self._somevalue = value
def def_attr(self):
print('calling delete method to delete value')
def self._somevalue
x = property(get_value, set_value, del_attr, "I'm the 'x' property.")
obj = Some_Class()
obj.x = 10
print(obj.x + 2)
del obj.x
obj.x
2、第二种形式
class Some_Class(self):
_x = None
def __init__(self):
self._x = None
@property
def x(self):
print('calling get method to return value')
return self._x
@x.setter
def x(self, value):
print('calling set method to set value')
self._x = value
@x.deleter
def x(self):
print('calling delete method to delete value')
del self._x
以上我们可以总结出 property 的优势:
1、代码更简洁,可读性更强
2、更好的管理属性的访问。property 将对属性的访问直接转换为对对应的 get、set 等相关函数的调用,属性能够更好地被控制和管理,常见的应用场景如设置校验(如检查电子邮件地址是否合法)、检查赋值的范围(某个变量的赋值范围必须在 0 到 10 之间)以及对某个属性进行二次计算之后再返回给用户(将 RGB 形式表示的颜色转换为#**)或者计算某个依赖于其他属性的属性。
class Date(object):
def __init__(self, year, month, day):
self.year = year
self.month = month
self.day = day
def get_date(self):
return self.year + '-' + self.month + '-' + self.day
def set_date(self, date_as_string):
year, month, day = date_as_string.split('-')
if not (2000 <= year <= 2017 and 0 <= month <= 12 and 0 <= day <= 31):
print('year should be in [2000:2017]')
print('month should be in [0:12]')
print('day should be in [0, 31]')
raise AssertionError
self.year = year
self.month = month
self.day = day
date = property(get_date, set_date)
创建一个 property 实际上就是将其属性的访问与特定的函数关联起来,相对于标准属性的访问,property 的作用相当于一个分发器,对某个属性的访问并不直接操作具体的对象,而对标准属性的访问没有中间这一层,直接访问存储属性的对象:
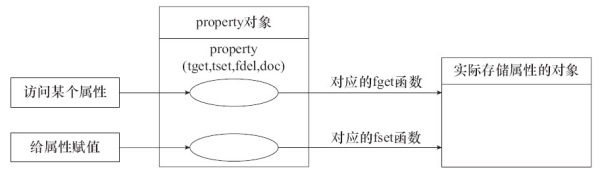
3、代码可维护性更好。property 对属性进行再包装,以类似于接口的形式呈现给用户,以统一的语法来访问属性,当具体实现需要改变的时候,访问的方式仍然可以保持一致。
4、控制属性访问权限,提高数据安全性。如果用户想设置某个属性为只读,来看看 property 是如何实现的。
class PropertyTest(object):
def __init__(self):
self.__var1 = 20
@property
def x(self):
return self.__var1
pt = PropertyTest()
print(pt.x)
pt.x = 12
注意这样使用 property 并不能真正意义达到属性只读的目的,正如以双下划线命令的变量并不是真正的私有变量一样,我们还是可以通过pt._PropertyTest__var1 = 30来修改属性。稍后我们会讨论如何实现真正意义上的只读和私有变量。
既然 property 本质是特殊类,那么就可以被继承,我们就可以自定义 property:
def update_meta(self, other):
self.__name__ = other.__name__
self.__doc__ = other.__doc__
self.__dict__.update(other.__dict__)
return self
class UserProperty(property):
def __new__(cls, fget=None, fset=None, fdel=None, doc=None):
if fget is not None:
def __get__(obj, objtype=None, name=fget.__name__):
fegt = getattr(obj, name)
return fget()
fget = update_meta(__get__, fget)
if fset is not None:
def __set__(obj, value, name=fset.__name__):
fset = getattr(obj, name)
return fset(value)
fset = update_meta(__set__, fset)
if fdel is not None:
def __delete__(obj, name=fdel.__name__):
fdel = getattr(obj, name)
return fdel()
fdel = update_meta(__delete__, fdel)
return property(fget, fset, fdel, doc)
class C(object):
def get(self):
return self._x
def set(self, x):
self._x = x
def delete(self):
del self._x
x = UserProperty(get, set, delete)
c = C()
c.x = 1
print(c.x)
def c.x
UserProperty 继承自 property,其构造函数 __ new __(cls, fget=None, fset=None, fdel=None, doc=None) 中重新定义了 fget() 、 fset() 以及 fdel() 方法以满足用户特定的需要,最后返回的对象实际还是 property 的实例,因此用户能够像使用 property 一样使用 UserProperty。
使用 property 并不能真正完全达到属性只读的目的,用户仍然可以绕过阻碍来修改变量。我们来看看一个可行的实现:
def ro_property(obj, name, value):
setattr(obj.__class__, name, property(lambda obj: obj.__dict__["__" + name]))
setattr(obj, "__" + name, value)
class ROClass(object):
def __init__(self, name, available):
ro_property(self, "name", name)
self.available = available
a = ROClass("read only", True)
print(a.name)
a._Article__name = "modify"
print(a.__dict__)
print(ROClass.__dict__)
print(a.name)
建议 62:掌握 metaclass
关于元类这知识点,推荐stackoverflow上Jerub的回答
这里有中文翻译
建议 63:熟悉 Python 对象协议
因为 Python 是一门动态语言,Duck Typing 的概念遍布其中,所以其中的 Concept 并不以类型的约束为载体,而另外使用称为协议的概念。
In [1]: class Object(object):
...: def __str__(self):
...: print('calling __str__')
...: return super(Object, self).__str__()
...:
In [2]: o = Object()
In [3]: print('%s' % o)
calling __str__
<__main__.Object object at 0x7f133ff20160>
比如在字符串格式化中,如果有占位符 %s,那么按照字符串转换的协议,Python 会自动地调用相应对象的 __ str __() 方法。
总结一下 Python 中的协议:
1、类型转换协议:__str __ () 、__repr __ ()、__init __ ()、__long __ ()、__float __ ()、 __ nonzero __() 等。
2、比较大小的协议:__cmp __ (),当两者相等时,返回 0,当 self < other 时返回负值,反之返回正值。同时 Python 又有 __ eq __ ()、 __ ne __ ()、 __ lt __ ()、 __ gt __ () 等方法来实现相等、不等、小于和大于的判定。这也就是 Python 对 ==、!=、< 和 > 等操作符的进行重载的支撑机制。
3、数值相关的协议:

其中有个 Python 中特有的概念:反运算。以something + other为例,调用的是something的 __ add __ (),若没有定义 __ add __ (),这时候 Python 有一个反运算的协议,查看other有没有 __ radd __ (),如果有,则以something为参数调用。
4、容器类型协议:容器的协议是非常浅显的,既然为容器,那么必然要有协议查询内含多少对象,在 Python 中,就是要支持内置函数 len(),通过 __ len __ () 来完成,一目了然。而 __ getitem __ ()、 __ setitem __ ()、 __ delitem __ () 则对应读、写和删除,也很好理解。 __ iter __ () 实现了迭代器协议,而 __ reversed __ () 则提供对内置函数 reversed() 的支持。容器类型中最有特色的是对成员关系的判断符 in 和 not in 的支持,这个方法叫 __ contains __ (),只要支持这个函数就能够使用 in 和 not in 运算符了。
5、可调用对象协议:所谓可调用对象,即类似函数对象,能够让类实例表现得像函数一样,这样就可以让每一个函数调用都有所不同。
In [1]: class Functor(object):
...: def __init__(self, context):
...: self._context = context
...: def __call__(self):
...: print('do something with %s' % self._context)
...:
In [2]: lai_functor = Functor('lai')
In [3]: yong_functor = Functor('yong')
In [4]: lai_functor()
do something with lai
In [5]: yong_functor()
do something with yong
6、还有一个可哈希对象,它是通过 __ hash __() 方法来支持 hash() 这个内置函数的,这在创建自己的类型时非常有用,因为只有支持可哈希协议的类型才能作为 dict 的键类型(不过只要继承自 object 的新式类就默认支持了)。
7、上下文管理器协议:也就是对with语句的支持,该协议通过 __ enter __ ()和 __ exit __ ()两个方法来实现对资源的清理,确保资源无论在什么情况下都会正常清理:
class Closer:
def __init__(self):
self.obj = obj
def __enter__(self):
return self.obj
def __exit__(self, exception_type, exception_val, trace):
try:
self.obj.close()
except AttributeError:
print('Not closeable.')
return True
这里 Closer 类似的类已经在标准库中存在,就是 contextlib 里的 closing。
以上就是常用的对象协议,灵活地用这些协议,我们可以写出更为 Pythonic 的代码,它更像是声明,没有语言上的约束,需要大家共同遵守。
建议 64:利用操作符重载实现中缀语法
熟悉 Shell 脚本编程应该熟悉/管道符号,用以连接两个程序的输入输出。如按字母表反序遍历当前目录的文件与子目录:
$ ls | sort -r
Videos/
Templates/
Public/
Pictures/
Music/
examples.desktop
Dropbox/
Downloads/
Documents/
Desktop/
管道的处理非常清晰,因为它是中缀语法。而我们常用的 Python 是前缀语法,比如类似的 Python 代码应该是 sort(ls(), reverse=True)。
Julien Palard 开发了一个 pipe 库,利用/来简化代码,也就是重载了 __ ror __ () 方法:
class Pipe:
def __init__(self, function):
self.function = function
def __ror__(self, other):
return self.function(other)
def __call__(self, *args, **kwargs):
return Pipe(lambda x: self.function(x, *args, **kwargs))
这个 Pipe 类可以当成函数的 decorator 来使用。比如在列表中筛选数据:
@Pipe
def where(iterable, predicate):
return (x for x in iterable if (predicate(x)))
pipe 库内置了一堆这样的处理函数,比如 sum、select、where 等函数尽在其中,请看以下代码:
fib() | take_while(lambda x: x < 1000000) \
| where(lambda x: x % 2) \
| select(lambda x: x * x) \
| sum()
这样写的代码,意义是不是一目了然呢?就是找出小于 1000000 的斐波那契数,并计算其中的偶数的平方之和。
我们可以使用pip3 install pipe安装,安装完后测试:
In [1]: from pipe import *
In [2]: [1, 2, 3, 4, 5] | where(lambda x: x % 2) | tail(2) | select(lambda x: x * x) | add
Out[2]: 34
此外,pipe 是惰性求值的,所以我们完全可以弄一个无穷生成器而不用担心内存被用完:
In [3]: def fib():
...: a, b = 0, 1
...: while True:
...: yield a
...: a, b = b, a + b
...:
In [4]: euler2 = fib() | where(lambda x: x % 2 ==0) | take_while(lambda x: x < 400000) | add
In [5]: euler2
Out[5]: 257114
读取文件,统计文件中每个单词出现的次数,然后按照次数从高到低对单词排序:
from __future__ import print_function
from re import split
from pipe import *
with open("test_descriptor.py") as f:
print(f.read()
| Pipe(lambda x: split("/W+", x))
| Pipe(lambda x:(i for i in x if i.strip()))
| groupby(lambda x:x)
| select(lambda x:(x[0], (x[1] | count)))
| sort(key=lambda x: x[1], reverse=True)
)
建议 65:熟悉 Python 的迭代器协议
首先介绍一下 iter() 函数,iter() 可以输入两个实参,为了简化,第二个可选参数可以忽略。iter() 函数返回一个迭代器对象,接受的参数是一个实现了 __ iter __ () 方法的容器或迭代器(精确来说,还支持仅有 __ getitem __ () 方法的容器)。对于容器而言, __ iter __ () 方法返回一个迭代器对象,而对迭代器而言,它的 __ iter __ () 方法返回其自身。
所谓协议,是一种松散的约定,并没有相应的接口定义,所以把协议简单归纳如下:
实现 __ iter __ () 方法,返回一个迭代器
实现 next() 方法,返回当前的元素,并指向下一个元素的位置,如果当前位置已无元素,则抛出 StopIteration 异常
没错,其实 for 语句就是对获取容器的迭代器、调用迭代器的 next() 方法以及对 StopIteration 进行处理等流程进行封装的语法糖(类似的语法糖还有 in/not in 语句)。
迭代器最大的好处是定义了统一的访问容器(或集合)的统一接口,所以程序员可以随时定义自己的迭代器,只要实现了迭代器协议即可。除此之外,迭代器还有惰性求值的特性,它仅可以在迭代至当前元素时才计算(或读取)该元素的值,在此之前可以不存在,在此之后也可以销毁,也就是说不需要在遍历之前实现准备好整个迭代过程中的所有元素,所以非常适合遍历无穷个元素的集合或或巨大的事物(斐波那契数列、文件):
class Fib(object):
def __init__(self):
self._a, self._b = 0, 1
def __iter__(self):
return self
def next(self):
self._a, self._b = self._b, self._a + self._b
return self._a
for i, f in enumerate(Fib()):
print(f)
if i > 10:
break
下面来看看与迭代有关的标准库 itertools。
itertools 的目标是提供一系列计算快速、内存高效的函数,这些函数可以单独使用,也可以进行组合,这个模块受到了 Haskell 等函数式编程语言的启发,所以大量使用 itertools 模块中的函数的代码,看起来有点像函数式编程语言。比如 sum(imap(operator.mul, vector1, vector2)) 能够用来运行两个向量的对应元素乘积之和。
itertools 提供了以下几个有用的函数:chain() 用以同时连续地迭代多个序列;compress()、dropwhile() 和 takewhile() 能用遴选序列元素;tee() 就像同名的 UNIX 应用程序,对序列作 n 次迭代;而 groupby 的效果类似 SQL 中相同拼写的关键字所带的效果。
[k for k, g in groupby("AAAABBBCCDAABB")] --> A B C D A B
[list(g) for k, g in groupby("AAAABBBCCD")] --> AAAA BBB CC D
除了这些针对有限元素的迭代帮助函数之外,还有 count()、cycle()、repeat() 等函数产生无穷序列,这 3 个函数就分别可以产生算术递增数列、无限重复实参的序列和重复产生同一个值的序列。
组合函数意义product()计算 m 个序列的 n 次笛卡尔积permutations()产生全排列combinations()产生无重复元素的组合combinations_with_replacement()产生有重复元素的组合
In [1]: from itertools import *
In [2]: list(product('ABCD', repeat=2))
Out[2]:
[('A', 'A'),
('A', 'B'),
('A', 'C'),
('A', 'D'),
('B', 'A'),
('B', 'B'),
('B', 'C'),
('B', 'D'),
('C', 'A'),
('C', 'B'),
('C', 'C'),
('C', 'D'),
('D', 'A'),
('D', 'B'),
('D', 'C'),
('D', 'D')]
# 其中 product() 可以接受多个序列
In [5]: for i in product('ABC', '123', repeat=2):
...: print(''.join(i))
...:
A1A1
A1A2
A1A3
A1B1
A1B2
A1B3
A1C1
A1C2
...
建议 66:熟悉 Python 的生成器
生成器,顾名思义,就是按一定的算法生成一个序列。
迭代器虽然在某些场景表现得像生成器,但它绝非生成器;反而是生成器实现了迭代器协议的,可以在一定程度上看作迭代器。
如果一个函数,使用了 yield 关键字,那么它就是一个生成器函数。当调用生成器函数时,它返回一个迭代器,不过这个迭代器是以生成器对象的形式出现的:
In [1]: def fib(n):
...: a, b = 0, 1
...: while a < n:
...: yield a
...: a, b = b, a + b
...: for i, f in enumerate(fib(10)):
...: print(f)
...:
0
1
1
2
3
5
8
In [2]: f = fib(10)
In [3]: type(f)
Out[3]: generator
In [4]: dir(f)
Out[4]:
['__class__',
'__del__',
'__delattr__',
'__dir__',
'__doc__',
'__eq__',
'__format__',
'__ge__',
'__getattribute__',
'__gt__',
'__hash__',
'__init__',
'__iter__',
'__le__',
'__lt__',
'__name__',
'__ne__',
'__new__',
'__next__',
'__qualname__',
'__reduce__',
'__reduce_ex__',
'__repr__',
'__setattr__',
'__sizeof__',
'__str__',
'__subclasshook__',
'close',
'gi_code',
'gi_frame',
'gi_running',
'gi_yieldfrom',
'send',
'throw']
可以看到它返回的是一个 generator 类型的对象,这个对象带有 __ iter __ ()和 __ next __ ()方法,可见确实是一个迭代器。
分析:
1.每一个生成器函数调用之后,它的函数并不执行,而是到第一次调用 next() 的时候才开始执行;
2.yield 表达式的默认返回值为 None,当第一次调用 next() 方法时,生成器函数开始执行,执行到 yield 表达式为止;
3.再次调用next()方法,函数将在上次停止的地方继续执行。
send() 是全功能版本的 next(),或者说 next() 是 send()的快捷方式,相当于 send(None)。还记得 yield 表达式有一个返回值吗?send() 方法的作用就是控制这个返回值,使得 yield 表达式的返回值是它的实参。
除了能 yield 表达式的“返回值”之外,也可以让它抛出异常,这就是 throw() 方法的能力。
对于常规业务逻辑的代码来说,对特定的异常有很好的处理(比如将异常信息写入日志后优雅的返回),从而实现从外部影响生成器内部的控制流。
当调用 close() 方法时,yield 表达式就抛出 GeneratorExit 异常,生成器对象会自行处理这个异常。当调用 close() 方法,再次调用 next()、send() 会使生成器对象抛出 StopIteration 异常。换言之,这个生成器对象已经不再可用。当生成器对象被 GC 回收时,会自动调用 close()。
生成器还有两个很棒的用处:
1.实现 with 语句的上下文管理协议,利用的是调用生成器函数时函数体并不执行,当第一次调用 next() 方法时才开始执行,并执行到 yield 表达式后中止,直到下一次调用 next() 方法这个特性;
2.实现协程,利用的是 send()、throw()、close() 等特性。
第二个用处在下一个小节讲解,先看第一个:
In [1]: with open('/tmp/test.txt', 'w') as f:
...: f.write('Hello, context manager.')
...:
In [2]: from contextlib import contextmanager
In [3]: @contextmanager
...: def tag(name):
...: print('<%s>' % name)
...: yield
...: print('<%s>' % name)
...:
In [4]: with tag('h1'):
...: print('foo')
...:
<h1>
foo
<h1>
这是 Python 文档中的例子。通过 contextmanager 对 next()、throw()、close() 的封装,yield 大大简化了上下文管理器的编程复杂度,对提高代码可维护性有着极大的意义。除此之外,yield 和 contextmanager 也可以用以“池”模式中对资源的管理和回收,具体的实现留给大家去思考。
建议 67:基于生成器的协程及 greenlet
先介绍一下协程的概念:
协程,又称微线程和纤程等,据说源于 Simula 和 Modula-2 语言,现代编程语言基本上都支持这个特性,比如 Lua 和 ruby 都有类似的概念。
协程往往实现在语言的运行时库或虚拟机中,操作系统对其存在一无所知,所以又被称为用户空间线程或绿色线程。又因为大部分协程的实现是协作式而非抢占式的,需要用户自己去调度,所以通常无法利用多核,但用来执行协作式多任务非常合适。用协程来做的东西,用线程或进程通常也是一样可以做的,但往往多了许多加锁和通信的操作。
基于生产着消费者模型,比较抢占式多线程编程实现和协程编程实现。线程实现至少有两点硬伤:
对队列的操作需要有显式/隐式(使用线程安全的队列)的加锁操作。
消费者线程还要通过 sleep 把 CPU 资源适时地“谦让”给生产者线程使用,其中的适时是多久,基本上只能静态地使用经验,效果往往不尽如人意。
下面来看看协程的解决方案,代码来自廖雪峰 Python3 教程:
def consumer():
r = ''
while True:
n = yield r
if not n:
return
print('[CONSUMER] Consuming %s...' % n)
r = '200 OK'
def produce(c):
c.send(None)
n = 0
while n < 5:
n = n + 1
print('[PRODUCER] Producing %s...' % n)
r = c.send(n)
print('[PRODUCER] Consumer return: %s' % r)
c.close()
c = consumer()
produce(c)
执行结果:
[PRODUCER] Producing 1...
[CONSUMER] Consuming 1...
[PRODUCER] Consumer return: 200 OK
[PRODUCER] Producing 2...
[CONSUMER] Consuming 2...
[PRODUCER] Consumer return: 200 OK
[PRODUCER] Producing 3...
[CONSUMER] Consuming 3...
[PRODUCER] Consumer return: 200 OK
[PRODUCER] Producing 4...
[CONSUMER] Consuming 4...
[PRODUCER] Consumer return: 200 OK
[PRODUCER] Producing 5...
[CONSUMER] Consuming 5...
[PRODUCER] Consumer return: 200 OK
注意到consumer函数是一个generator,把一个consumer传入produce后:
1.首先调用c.send(None)启动生成器;
2.然后,一旦生产了东西,通过c.send(n)切换到consumer执行;
3.consumer通过yield拿到消息,处理,又通过yield把结果传回;
4.produce拿到consumer处理的结果,继续生产下一条消息;
5.produce决定不生产了,通过c.close()关闭consumer,整个过程结束。
整个流程无锁,由一个线程执行,produce和consumer协作完成任务,所以称为“协程”,而非线程的抢占式多任务。
最后套用Donald Knuth的一句话总结协程的特点:
“子程序就是协程的一种特例。”
greenlet 是一个 C 语言编写的程序库,它与 yield 关键字没有密切的关系。greenlet 这个库里最为关键的一个类型就是 PyGreenlet 对象,它是一个 C 结构体,每一个 PyGreenlet 都可以看到一个调用栈,从它的入口函数开始,所有的代码都在这个调用栈上运行。它能够随时记录代码运行现场,并随时中止,以及恢复。它跟 yield 所能够做到的相似,但更好的是它提供从一个 PyGreenlet 切换到另一个 PyGreenlet 的机制。
from greenlet import greenlet
def test1():
print(12)
gr2.switch()
print(34)
def test2():
print(56)
gr1.switch()
print(78)
gr1 = greenlet(test1)
gr2 = greenlet(test2)
gr1.switch()
协程虽然不能充分利用多核,但它跟异步 I/O 结合起来以后编写 I/O 密集型应用非常容易,能够在同步的代码表面下实现异步的执行,其中的代表当属将 greenlet 与 libevent/libev 结合起来的 gevent 程序库,它是 Python 网络编程库。最后,以 gevent 并发查询 DNS 的例子为例,使用它进行并发查询 n 个域名,能够获得几乎 n 倍的性能提升:
In [1]: import gevent
In [2]: from gevent import socket
In [3]: urls = ['www.baidu.com', 'www.python.org', 'www.qq.com']
In [4]: jobs = [gevent.spawn(socket.gethostbyname, url) for url in urls]
In [5]: gevent.joinall(jobs, timeout=2)
Out[5]:
[<Greenlet at 0x7f37e439c508>,
<Greenlet at 0x7f37e439c5a0>,
<Greenlet at 0x7f37e439c340>]
In [6]: [job.value for job in jobs]
Out[6]: ['115.239.211.112', '151.101.24.223', '182.254.34.74']
建议 68:理解 GIL 的局限性
多线程 Python 程序运行的速度比只有一个线程的时候还要慢,除了程序本身的并行性之外,很大程度上与 GIL 有关。由于 GIL 的存在,多线程编程在 Python 中并不理想。GIL 被称为全局解释器锁(Global Interpreter Lock),是 Python 虚拟机上用作互斥线程的一种机制,它的作用是保证任何情况下虚拟机中只会有一个线程被运行,而其他线程都处于等待 GIL 锁被释放的状态。不管是在单核系统还是多核系统中,始终只有一个获得了 GIL 锁的线程在运行,每次遇到 I/O 操作便会进行 GIL 锁的释放。
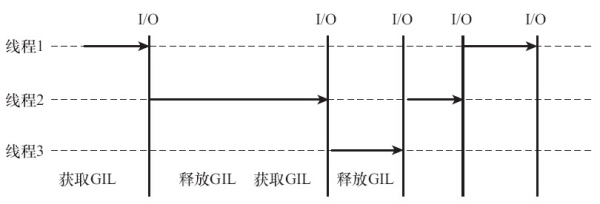
但如果是纯计算的程序,没有I/O操作,解释器则会根据sys.setcheckinterval的设置来自动进行线程间的切换,默认是每隔100个内部时钟就会释放GIL锁从而轮换到其他线程:

在单核 CPU 中,GIL 对多线程的执行并没有太大影响,因为单核上的多线程本质上就是顺序执行的。但对于多核 CPU,多线程并不能真正发挥优势带来效率上明显的提升,甚至在频繁 I/O 操作的情况下由于存在需要多次释放和申请 GIL 的情形,效率反而会下降。
那么 Python 解释器为什么要引入 GIL 呢?
我们知道 Python 中对象的管理与引用计数器密切相关,当计数器变为 0 的时候,该对象便会被垃圾回收器回收。当撤销一个对象的引用时,Python 解释器对对象以及其计数器的管理分为以下两步:
1.使引用计数值减1
2.判断该计数值是否为 0,如果为0,则销毁该对象
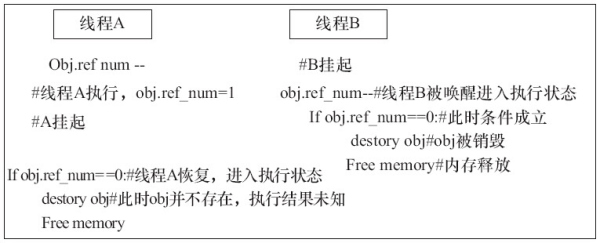
鉴于此,Python 引入了 GIL,以保证对虚拟机内部共享资源访问的互斥性。
GIL 的引入确实使得多线程不能再多核系统中发挥优势,但它也带来了一些好处:大大简化了 Python 线程中共享资源的管理,在单核 CPU 上,由于其本质是顺序执行的,一般情况下多线程能够获得较好的性能。此外,对于扩展的 C 程序的外部调用,即使其不是线程安全的,但由于 GIL 的存在,线程会阻塞直到外部调用函数返回,线程安全不再是一个问题。
在 Python3.2 中重新实现了 GIL,其实现机制主要集中在两个方面:一方面是使用固定的时间而不是固定数量的操作指令来进行线程的强制切换;另一个方面是在线程释放 GIL 后,开始等待,直到某个其他线程获取 GIL 后,再开始尝试去获取 GIL,这样虽然可以避免此前获得 GIL 的线程,不会立即再次获取 GIL,但仍然无法保证优先级高的线程优先获取 GIL。这种方式只能解决部分问题,并未改变 GIL 的本质。
Python 提供了其他方式可以绕过 GIL 的局限,比如使用多进程 multiprocess 模块或者采用 C 语言扩展的方式,以及通过 ctypes 和 C 动态库来充分利用物理内核的计算能力。
建议 69:对象的管理与垃圾回收
class Leak(object):
def __init__(self):
print('object with id %d was born' % id(self))
while(True):
A = Leak()
B = Leak()
A.b = B
B.a = A
A = None
B = None
运行上述程序,我们会发现 Python 占用的内存消耗一直在持续增长,直到最后内存耗光。
先简单谈谈 Python 中的内存管理的方式:
Python 使用引用计数器(Reference counting)的方法来管理内存中的对象,即针对每一个对象维护一个引用计数值来表示该对象当前有多少个引用。
当其他对象引用该对象时,其引用计数会增加 1,而删除一个队当前对象的引用,其引用计数会减 1。只有当引用计数的值为 0 时的时候该对象才会被垃圾收集器回收,因为它表示这个对象不再被其他对象引用,是个不可达对象。引用计数算法最明显的缺点是无法解决循环引用的问题,即两个对象相互引用。如同上述代码中A、B对象之间相互循环引用造成了内存泄露,因为两个对象的引用计数都不为 0,该对象也不会被垃圾回收器回收,而无限循环导致一直在申请内存而没有释放。
循环引用常常会在列表、元组、字典、实例以及函数使用时出现。对于由循环引用而导致的内存泄漏的情况,可以使用 Python 自带的一个 gc 模块,它可以用来跟踪对象的“入引用(incoming reference)“和”出引用(outgoing reference)”,并找出复杂数据结构之间的循环引用,同时回收内存垃圾。有两种方式可以触发垃圾回收:一种是通过显式地调用 gc.collect() 进行垃圾回收;还有一种是在创建新的对象为其分配内存的时候,检查 threshold 阈值,当对象的数量超过 threshold 的时候便自动进行垃圾回收。默认情况下阈值设为(700,10,10),并且 gc 的自动回收功能是开启的,这些可以通过 gc.isenabled() 查看:
In [1]: import gc
In [2]: print(gc.isenabled())
True
In [3]: gc.isenabled()
Out[3]: True
In [4]: gc.get_threshold()
Out[4]: (700, 10, 10)
所以修改之前的代码:
def main():
collected = gc.collect()
print("Garbage collector before running: collected {} objects.".format(collected))
print("Creating reference cycles...")
A = Leak()
B = Leak()
A.b = B
B.a = A
A = None
B = None
collected = gc.collect()
print(gc.garbage)
print("Garbage collector after running: collected {} objects".format(collected))
if __name__ == "__main__":
ret = main()
sys.exit(ret)
gc.garbage 返回的是由于循环引用而产生的不可达的垃圾对象的列表,输出为空表示内存中此时不存在垃圾对象。gc.collect() 显示所有收集和销毁的对象的数目,此处为 4(2 个对象 A、B,以及其实例属性 dict)。
我们再来考虑一个问题:如果在类 Leak 中添加析构方法 __ del __ (),会发现 gc.garbage 的输出不再为空,而是对象 A、B 的内存地址,也就是说这两个对象在内存中仍然以“垃圾”的形式存在。
这是什么原因呢?实际上当存在循环引用并且当这个环中存在多个析构方法时,垃圾回收器不能确定对象析构的顺序,所以为了安全起见仍然保持这些对象不被销毁。而当环被打破时,gc 在回收对象的时候便会再次自动调用 __ del __ () 方法。
gc 模块同时支持 DEBUG 模式,当设置 DEBUG 模式之后,对于循环引用造成的内存泄漏,gc 并不释放内存,而是输出更为详细的诊断信息为发现内存泄漏提供便利,从而方便程序员进行修复。更多 gc 模块可以参考文档 。
第 7 章 使用工具辅助项目开发
Python 项目的开发过程,其实就是一个或多个包的开发过程,而这个开发过程又由包的安装、管理、测试和发布等多个节点构成,所以这是一个复杂的过程,使用工具进行辅助开发有利于减少流程损耗,提升生产力。本章将介绍几个常用的、先进的工具,比如 setuptools、pip、paster、nose 和 Flask-PyPI-Proxy 等。
建议 70:从 PyPI 安装包
PyPI 全称 Python Package Index,直译过来就是“Python 包索引”,它是 Python 编程语言的软件仓库,类似 Perl 的 CPAN 或 Ruby 的 Gems。
$ tar zxvf requests-1.2.3.tar.gz
$ cd requests-1.2.3
$ python setup.py install
$ sudo aptitude install python-setuptools # 自动安装包
建议 71:使用 pip 和 yolk 安装、管理包
pip 常用命令:
$ pip install package_name
$ pip uninstall package_name
$ pip show package_name
$ pip freeze
建议 72:做 paster 创建包
distutils 标准库,至少提供了以下几方面的内容:
支持包的构建、安装、发布(打包)
支持 PyPI 的登记、上传
定义了扩展命令的协议,包括 distutils.cmd.Command 基类、distutils.commands 和 distutils.key_words 等入口点,为 setuptools 和 pip 等提供了基础设施。
要使用 distutils,按习惯需要编写一个 setup.py 文件,作为后续操作的入口点。在arithmetic.py同层目录下建立一个setup.py文件,内容如下:
from distutils.core import setup
setup(name="arithmetic",
version='1.0',
py_modules=["your_script_name"],
)
setup.py 文件的意义是执行时调用 distutils.core.setup() 函数,而实参是通过命名参数指定的。name 参数指定的是包名;version 指定的是版本;而 py_modules 参数是一个序列类型,里面包含需要安装的 Python 文件。
编写好 setup.py 文件以后,就可以使用 python setup.py install 进行安装了。
distutils 还带有其他命令,可以通过 python setup.py –help-commands 进行查询。
实际上若要把包提交到 PyPI,还要遵循 PEP241,给出足够多的元数据才行,比如对包的简短描述、详细描述、作者、作者邮箱、主页和授权方式等:
setup(
name='requests',
version=requests.__version__,
description='Python HTTP for Humans.',
long_description=open('README.rst').read() + '\n\n' +
open('HISTORY.rst').read(),
author='Kenneth Reitz',
author_email='me@kennethreitz.com',
url='http://python-requests.org',
packages=packages,
package_data={'': ['LICENSE', 'NOTICE'], 'requests': ['*.pem']},
package_dir={'requests': 'requests'},
include_package_data=True,
install_requires=requires,
license=open('LICENSE').read(),
zip_safe=False,
classifiers=(
'Development Status :: 5 - Production/Stable',
'Intended Audience :: Developers',
'Natural Language :: English',
'License :: OSI Approved :: Apache Software License',
'Programming Language :: Python',
'Programming Language :: Python :: 2.6',
'Programming Language :: Python :: 2.7',
'Programming Language :: Python :: 3',
'Programming Language :: Python :: 3.3',
),
)
包含太多内容了,如果每一个项目都手写很困难,最好找一个工具可以自动创建项目的 setup.py 文件以及相关的配置、目录等。Python 中做这种事的工具有好几个,做得最好的是 pastescript。pastescript 是一个有着良好插件机制的命令行工具,安装以后就可以使用 paster 命令,创建适用于 setuptools 的包文件结构。
安装好 pastescript 以后可以看到它注册了一个命令行入口 paster:
$ paster create --list-template # 查询目录安装的模板
$ paster create -o arithmethc-2 -t basic_package atithmetic # 为了 atithmetic 生成项目包
简单地填写几个问题以后,paster 就在 arithmetic-2 目录生成了名为 arithmetic 的包项目。
用上 –config 参数,它是一个类似 ini 文件格式的配置文件,可以在里面填好各个模板变量的值(查询模板有哪些变量用 –list-variables参数),然后就可以使用了。
[pastescript]
description = corp-prj
license_name =
keywords = Python
long_description = corp-prj
author = xxx corp
author_email = xxx@example.com
url = http://example.com
version = 0.0.1
以上配置文件使用paster create -t basic_package –config=”corp-prj-setup.cfg” arithmetic
建议 73:理解单元测试概念
单元测试用来验证程序单元的正确性,一般由开发人员完成,是测试过程的第一个环节,以确保缩写的代码符合软件需求和遵循开发目标。好的单元测试有以下好处:
减少了潜在 bug,提高了代码的质量。
大大缩减软件修复的成本
为集成测试提供基本保障
有效的单元测试应该从以下几个方面考虑:
测试先行,遵循单元测试步骤:
创建测试计划(Test Plan)
编写测试用例,准备测试数据
编写测试脚本
编写被测代码,在代码完成之后执行测试脚本
修正代码缺陷,重新测试直到代码可接受为止
遵循单元测试基本原则:
一致性:避免currenttime = time.localtime()这种不确定执行结果的语句
原子性:执行结果只有 True 或 False 两种
单一职责:测试应该基于情景(scenario)和行为,而不是方法。如果一个方法对应着多种行为,应该有多个测试用例;而一个行为即使对应多个方法也只能有一个测试用例
隔离性:不能依赖于具体的环境设置,如数据库的访问、环境变量的设置、系统的时间等;也不能依赖于其他的测试用例以及测试执行的顺序,并且无条件逻辑依赖。单元测试的所有输入应该是确定的,方法的行为和结构应是可以预测的。
使用单元测试框架,在单元测试方面常见的测试框架有 PyUnit 等,它是 JUnit 的 Python 版本,在 Python2.1 之前需要单独安装,在 Python2.1 之后它成为了一个标准库,名为 unittest。它支持单元测试自动化,可以共享地进行测试环境的设置和清理,支持测试用例的聚集以及独立的测试报告框架。unittest 相关的概念主要有以下 4 个:
测试固件(test fixtures):测试相关的准备工作和清理工作,基于类 TestCase 创建测试固件的时候通常需要重新实现 setUp() 和 tearDown() 方法。当定义了这些方法的时候,测试运行器会在运行测试之前和之后分别调用这两个方法
测试用例(test case):最小的测试单元,通常基于 TestCase 构建
测试用例集(test suite):测试用例的集合,使用 TestSuite 类来实现,除了可以包含 TestCase 外,也可以包含 TestSuite
测试运行器(test runner):控制和驱动整个单元测试过程,一般使用 TestRunner 类作为测试用例的基本执行环境,常用的运行器为 TextTestRunner,它是 TestRunner 的子类,以文字方式运行测试并报告结果。
# 测试以下类
class MyCal(object):
def add(self, a, b):
return a + b
def sub(self, a, b):
return a - b
# 测试
class MyCalTest(unittest.TestCase):
def setUp(self):
print('running set up')
def tearDown(self):
print('running teardown')
self.mycal = None
def testAdd(self):
self.assertEqual(self.mycal.add(-1, 7), 6)
def testSub(self):
self.assertEqual(self.mycal.sub(10, 2), 8)
suite = unittest.TestSuite()
suite.addTest(MyCalTest("testAdd"))
suite.addTest(MyCalTest("testSub"))
runner = unittest.TextTestRunner()
runner.run(suite)
运行 python3 -m unittest -v MyCalTest 得到测试结果。
参考资料:https://zhuanlan.zhihu.com/p/26760180